How to extract subtitle file from Capcut project with python for FREE
Summary
Capcut requires a paid version to export text as subtitle file(.srt), but with the simple code introduced in this short post, you should be able export your subtitle to a .srt file from a Capcut project.
Preparation
First of all, you need to identify the file that records all your Capcut project data. For this, open up the project and you can find the project path in the detail tab. 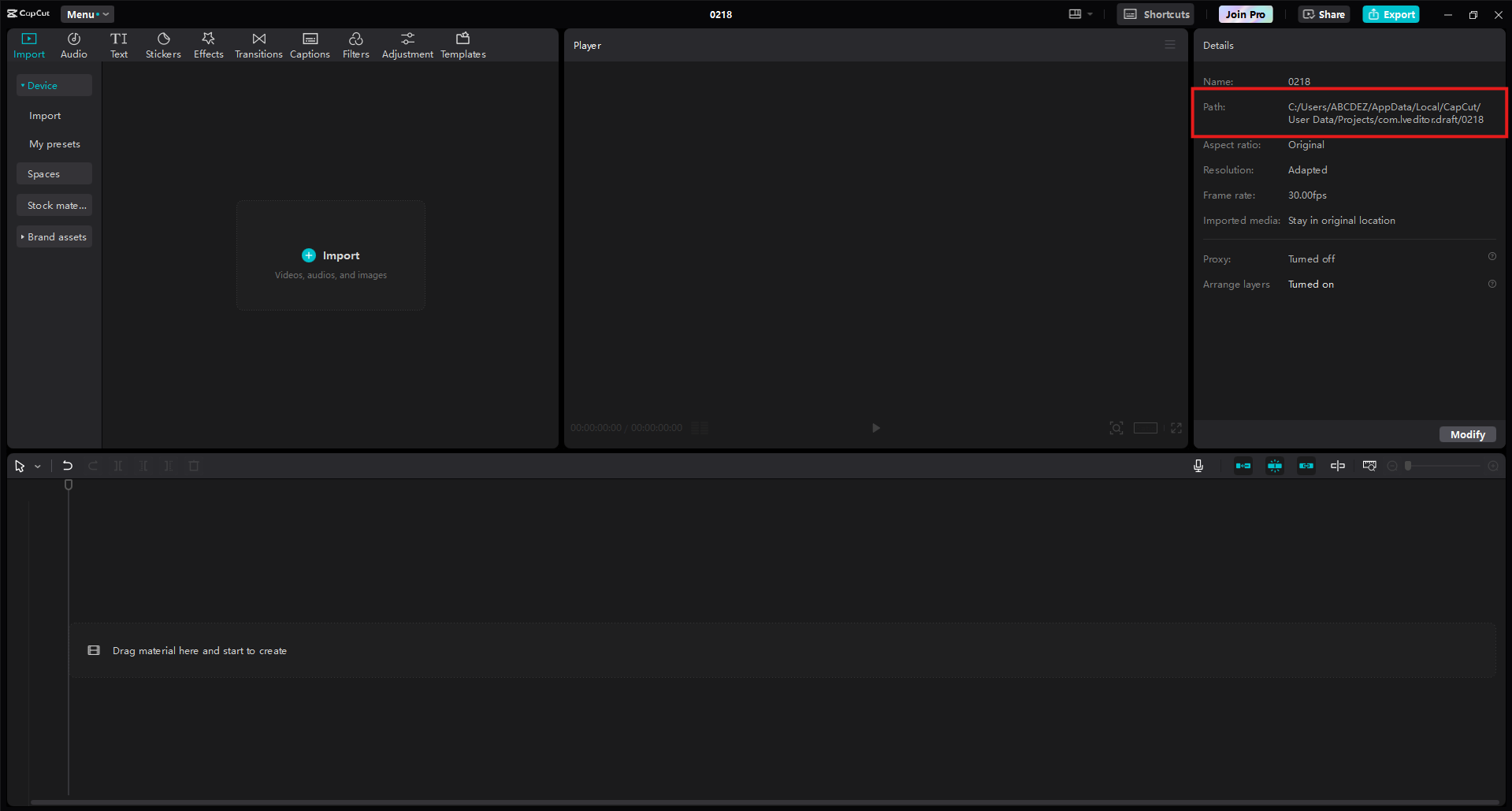
In the Path, you'll find a file with name draft_content.json if you are in Windows, draft_info.json if you are using Mac.
File path
Example project path in Windows:
Example project path in Mac: Replace{user} with your windows user, {project} with your Capcut project name. Load the file into python
Since this is a json file, we can just use the json package and load it into python as a dictionary with the code below:
import json
def parse_json_file(file_path: str) -> dict:
d = None
with open(file_path) as f:
d = json.load(f)
return d
Extract the text in the project
First we define a function to get all the text we added to the project.
def get_text_contents(data:dict) -> list:
texts = data['materials']['texts']
res = list()
for t in texts:
d = dict()
d['id'] = t['id']
d['text'] = json.loads(t['content'])['text']
res.append(d)
return res
Extract start time and duration from project
In order to create .srt file, for each text, we also need to know the start and end time of the text. In Capcut project, we have start time and duration of each text defined in microsecond as an integer. We calculate end time by adding duration to start time. Then we format the microsecond into what we need for .srt file. See info block for more detail on the format and the function format_microseconds in below code blow:
def get_text_durations(data) -> list:
tracks = data['tracks']
res = list()
for t in tracks:
segments = t['segments']
for s in segments:
d = dict()
start_time:int = s['target_timerange']['start']
end_time:int = start_time + s['target_timerange']['duration']
mid = s.get('material_id')
if mid is None: continue
d['id'] = mid
d['start_time'] = format_microseconds(start_time)
d['end_time'] = format_microseconds(end_time)
res.append(d)
return res
format time
Time in Capcut project is in microseconds, but we need it to be in hh:mm:ss,fff format, where fff is millisecond. We introduce below function to do format the int microseconds to a string in mentioned format:
def format_microseconds(us: int) -> str:
ms = us // 1_000
hours = ms // 3_600_000
minutes = (ms % 3_600_000) // 60_000
seconds = (ms % 60_000) // 1_000
milliseconds = ms % 1_000
return f"{hours:02}:{minutes:02}:{seconds:02},{milliseconds:03}"
Note
1_000 is just 1000, _ is just there for readability.
Join time and text
Now with texts and start and times extracted, we need to join them together. You may notice that we have extracted ids along with the texts and times.
import pandas as pd
def get_record_table(data:dict)->pd.DataFrame
duration = pd.DataFrame(get_text_durations(data))
content = pd.DataFrame(get_text_contents(data))
records = pd.merge(duration, content, on='id', how='inner')
records = records.sort_values(by=['start_time'])
return records
Generate .srt file
Now that we have all the functions to extract the data implemented, we are ready to start creating the record for each subtitle in the .srt format. See below info block for details on format.
def generate_srt_file(out_path:str, record:pd.DataFrame) -> None:
records = record.to_dict(orient='records')
srt = ''
for i in range(len(records)):
srt += f"{i+1}\n"
srt += f"{records[i]['start_time']} --> {records[i]['end_time']}\n"
srt += f"{records[i]['text']}\n\n"
with open(out_path, "w") as file:
file.write(srt)
format
.srt file normally have each record in below format:
hh:mm:ss,fff {i} is the index{text} is the content of the subtitle. An example of this is With above function ready, now you should be able to glue everything together and generate the file.
file_path = "C:\Users\{user}\AppData\Local\CapCut\User Data\Projects\com.lveditor.draft\{project}"
data = parse_json_file(file_path)
data1 = get_record_table(data)
generate_srt_file("{C:\{out}\{path}}", data1)